
¿Quieres profundizar? En nuestro blog: mejores herramientas de monitorización open source.
Sin monitorización profesional, el equipo técnico opera en modo apagar fuegos:
servidores, redes, almacenamiento, servicios
APM, métricas custom, latencias, errores
todos los logs en un solo sitio, búsqueda rápida, retención configurable
sigue una petición a través de todos los servicios
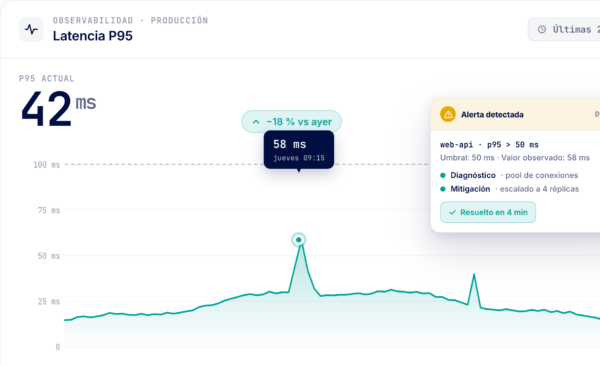
umbrales adaptativos, no spam de notificaciones
visibilidad para perfiles técnicos y para negocio
alerta al técnico de guardia automáticamente
cada incidente deja aprendizaje



Una tienda online de alta concurrencia que se caía en cada pico de tráfico, con cerca de 50 personas de atención al cliente dependiendo de ella a diario.
Un stack básico con métricas y alertas funciona en 1-2 semanas. Observabilidad completa (logs centralizados, trazas distribuidas, APM integrado) en 3-6 semanas según complejidad del sistema.
Depende del caso. Open source (Prometheus + Grafana + Loki) es muy potente y económico, pero requiere operación. SaaS (Datadog, New Relic) es plug-and-play pero caro al escalar. Lo discutimos en el diagnóstico.
Podemos integrar nuestro equipo en el on-call si lo necesitas, o entregar la operación de alertas a tu equipo con runbooks claros. Las dos modalidades funcionan.
Auditamos lo que tienes y proponemos evolución. Muchas veces no hay que tirar nada — solo mejorar coverage, ajustar umbrales y añadir observabilidad de aplicación.
Sí. Dashboards públicos por cliente (status page), informes mensuales de SLA, reportes ejecutivos. Es una de las cosas más valoradas en el Caso 04.